I recently was involved in an issue where error messages where being generated in the vmkernel.log and found out the cause was related to the maximum LUNs being increased in vSphere 6 from 255 to 1024. The error messages themselves were related to the fact that our Protocol Endpoint (PE) for VVols is advertised as LUN 256 and with a recent change in 6.0U2 related to PDL assessment a LUN that returns unexpected output upon query causes the error messages similar to below from a VMTN thread:
2016-04-05T14:27:05.577Z cpu6:33386)WARNING: NMP: nmp_PathDetermineFailure:2973: Cmd (0x28) PDL error (0x5/0x25/0x0) – path vmhba2:C0:T2:L256 device naa.2ff70002ac014e9d – triggering path failover
2016-04-05T14:27:05.577Z cpu6:33386)WARNING: NMP: nmpCompleteRetryForPath:382: Logical device “naa.2ff70002ac014e9d”: awaiting fast path state update before retrying failed command again…
2016-04-05T14:27:06.577Z cpu9:57333)WARNING: NMP: nmpDeviceAttemptFailover:603: Retry world failover device “naa.2ff70002ac014e9d” – issuing command 0x43a5cc84e400
2016-04-05T14:27:06.577Z cpu6:33386)WARNING: NMP: nmpCompleteRetryForPath:352: Retry cmd 0x28 (0x43a5cc84e400) to dev “naa.2ff70002ac014e9d” failed on path “vmhba2:C0:T3:L256” H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0.
2016-04-05T14:27:06.577Z cpu6:33386)WARNING: NMP: nmp_PathDetermineFailure:2973: Cmd (0x28) PDL error (0x5/0x25/0x0) – path vmhba2:C0:T3:L256 device naa.2ff70002ac014e9d – triggering path failover
Note the L256 in the above path that is related to LUN 256 (Protocol Endpoint) which is not a traditional LUN in the sense as it has no storage allocated to it and serves as an administrative LUN (LU_CONG) to access VVol sub-LUNs. Here’s some detail on the PDL change in vSphere 6.0 U2 and subsequent errors that it may cause:
[important]
New Issue ESXi 6.0 Update 2 hosts connected to certain storage arrays with a particular version of the firmware might see I/O timeouts and subsequent aborts When ESXi 6.0 Update 2 hosts connected to certain storage arrays with a particular version of the firmware send requests for SMART data to the storage array, and if the array responds with a PDL error, the PDL response behavior in 6.0 update 2 might result in a condition where these failed commands are continuously retried thereby blocking other commands. This error results in widespread I/O timeouts and subsequent aborts.
Also, the ESXi hosts might take a long time to reconnect to the vCenter Server after reboot or the hosts might go into a Not Responding state in the vCenter Server. Storage-related tasks such as HBA rescan might take a very long time to complete.
Workaround: To resolve this issue, see Knowledge Base article 2133286.
[/important]
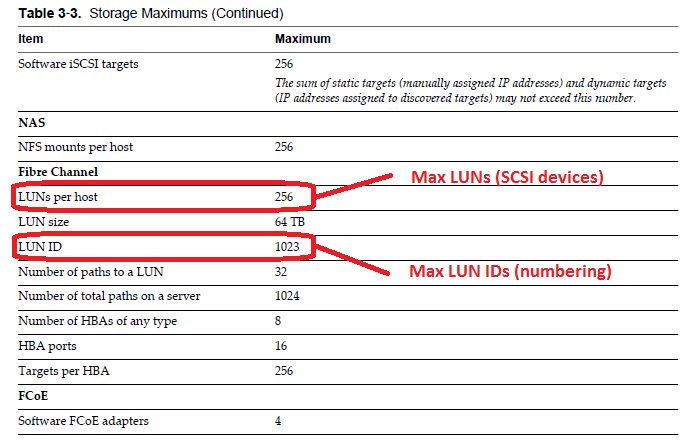
The solution to eliminate these errors seems to be to change Disk.MaxLUN parameter on your ESXi Hosts to 255 for or below as this KB article outlines. Note the KB article confirms the change in max LUNs to 1024 in vSphere 6.0. But also note that this change just impacts the LUN numbering as the max supported SCSI devices remains at 256, so essentially you can have LUNs numbered higher than 255 now but you are still limited to 256 total LUNs per host as documented in the vSphere 6.0 maximum configs doc.