Another year, another VMworld, this one being #12 for me, wow has it really been 12 years of going to VMworld. I’ve never in my professional career gone to any conference that many times. I think that is a largely a testament to how relevant VMware has managed to stay in the ever changing IT landscape that they have made all the right moves to stay fresh and competitive. This VMworld might have been called Containerworld instead with all the announcements and focus that VMworld has put into their container strategy, but more on that in a bit. As usual the event goes by all too fast but I have to admit overall this was probably one of the most enjoyable VMworld’s that I’ve been too in a long while. Seeing old friends and hanging out with them is always a highlight for me and making new friends always is great as well. So let’s get on with my thoughts and observations from VMworld 2019:
Before I dive in I first wanted to highlight this cool VMworld infographic made by my good buddy David Marshall.
The Location
After a 3 year run in Las Vegas, VMworld has finally and inevitably moved back to San Francisco having mainly moved because of construction and renovations being doing at Moscone Center the past few years. Now San Francisco has some cool things to see and do but the area around Moscone isn’t all that great. The big issues with it are the very expensive hotel rooms ($350+/night), less centrally located (caters to the western crowd) and the big one dealing with all the crap on the street and the homeless crowd. Also everything in SF shuts down way early, by 10pm everything around Moscone is super quiet which is a sharp contrast to Vegas where you can go all night every night. Everyone I talked to did not like VMworld being back in SF one bit and would prefer it being in Vegas which is much better equipped to handle large conferences. I know it is more convenient for VMware being in the bay area but is it far less convenient for the people that matter the most, the attendees. I really hope VMware shifts it back to Vegas at some point as VMworld 2020 is back in San Francisco.
 How many people attended VMworld?
How many people attended VMworld?
According to VMware around 20,000 which puts it about the same or a bit less than last year. However it felt like there was less people there, again it may have been the whole back in SF thing which is a turn off for many. VMworld attendance peaked in 2014 at 26,000, it was at 23,000 in 2015 and 2016 and then dropped off from there. While this number is a good general indicator of how popular an event is the number that matters is how many of that 20,000 are VMware staff, vendors, press, analysts, partners and customers. Unfortunately only VMware knows that percentage mix. Suffice it to say VMworld still draws a good number of people, for comparison sake Cisco Live draws 30,000, Amazon re:Invent draws 50,000, Oracle OpenWorld draws 60,000 and SalesForce DreamForce draws 170,000. I have no idea how you fit 170,000 people in San Fransisco when 20,000 seems rather crowded.
What was announced at VMworld?
If you were hoping to tune in hearing about the next version of vSphere, this wasn’t the conference for you. Instead VMware focused all of their announcement around their latest acquisitions and container strategy with Kubernetes. Right off the bat on Day 1 Pat announced Project Tanzu in the keynote, Project Tanzu by itself isn’t really a product, it is basically a new brand name for VMware’s container app portfolio that is categorized into the typical container buckets of Build, Run and Manage. Within those buckets reside much of VMware’s new products and acquisitions.
 The Build bucket of Tanzu consists of VMware PKS, Pivotal, Bitnami and Heptio. These are all mostly acquisitions VMware has made with the Pivotal one still pending. This will provide VMware with a huge existing install base of Kubernetes apps and services that they can further integrate into their portfolio.
The Build bucket of Tanzu consists of VMware PKS, Pivotal, Bitnami and Heptio. These are all mostly acquisitions VMware has made with the Pivotal one still pending. This will provide VMware with a huge existing install base of Kubernetes apps and services that they can further integrate into their portfolio.
The Run bucket consists mainly of another new announcement, Project Pacific which basically embeds support for Kubernetes directly into vSphere. This is a big announcement as this time around VMware isn’t taking the spin-off or bolt on approach to containers like they did with Photon or vSphere Integrated Containers. This is full blown embedded directly into the core vSphere products much like they did with vSAN. Essentially it introduces the concept of Kubernetes Namespaces as an object in vSphere that can be managed right alongside traditional VMs, see below:
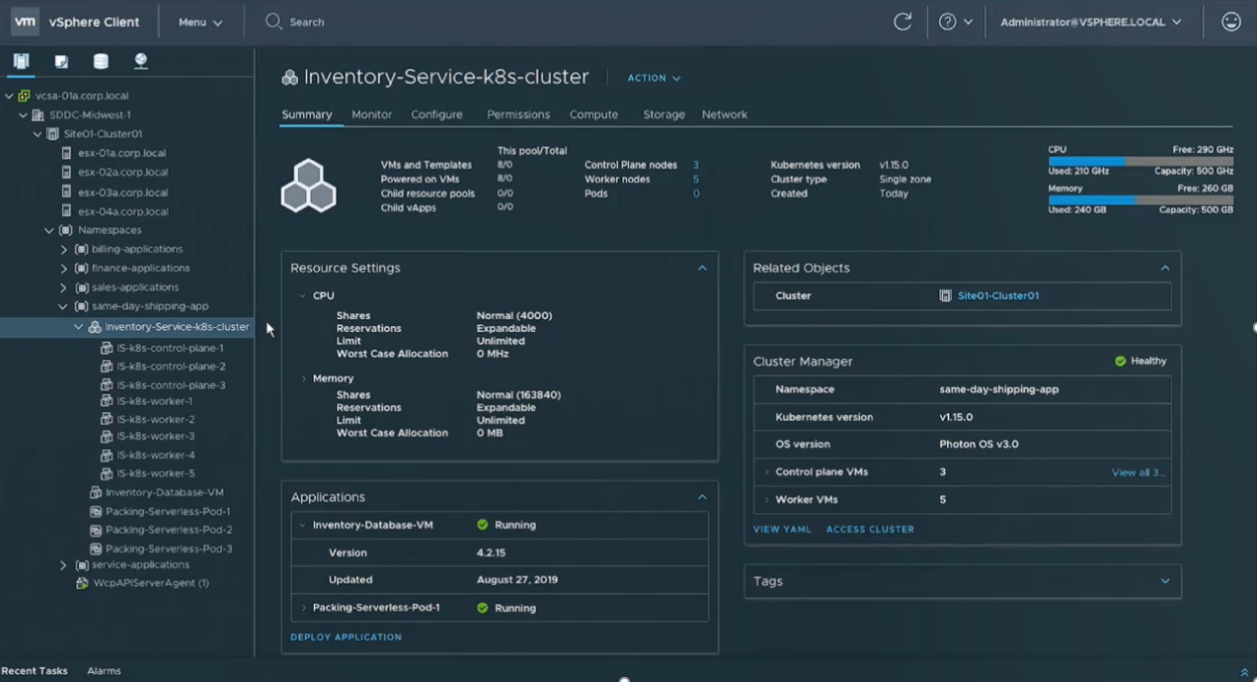 There is a good demo of this in the day 2 keynote. VMware also is claiming their is not performance tax for running Kubernetes inside of vSphere and that it is actually 8% faster then running it on bare metal. This support is currently a tech preview so it’s unknown which version of vSphere it will appear in but I’m guessing VMware wants to deliver this as soon as possible.
There is a good demo of this in the day 2 keynote. VMware also is claiming their is not performance tax for running Kubernetes inside of vSphere and that it is actually 8% faster then running it on bare metal. This support is currently a tech preview so it’s unknown which version of vSphere it will appear in but I’m guessing VMware wants to deliver this as soon as possible.
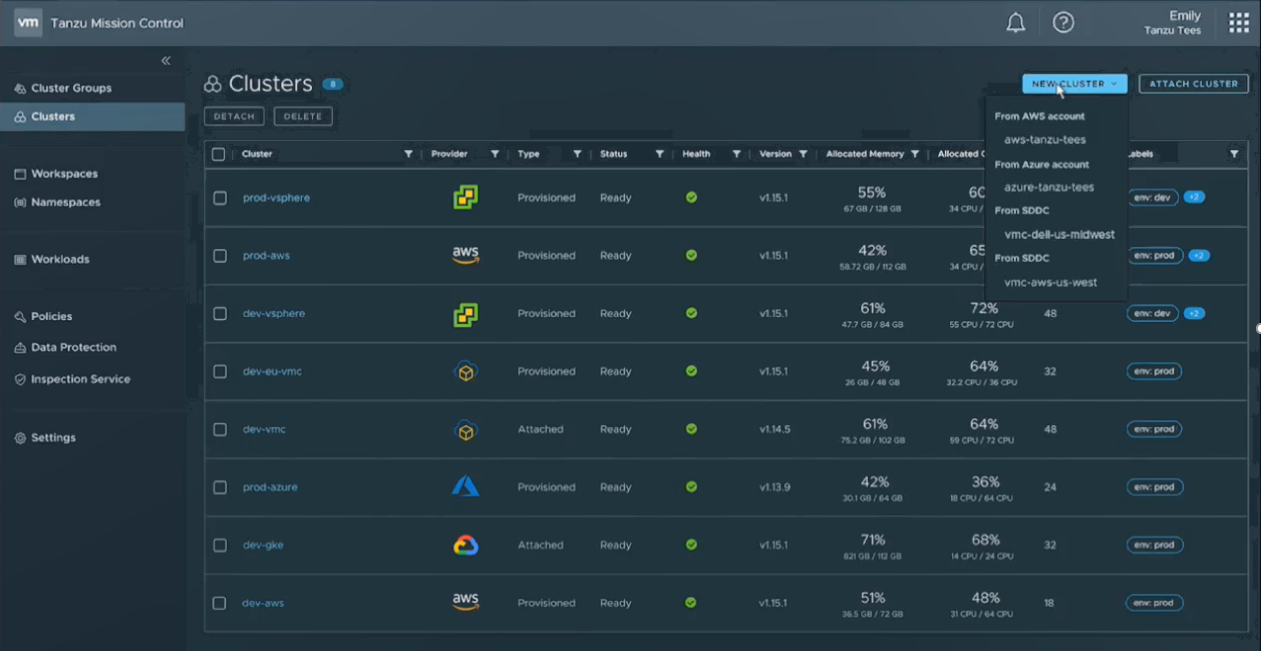
The Manage bucket consists of another new announcement, Tanzu Mission Control which a SaaS offering that will enable a single point of control to manage any Kubernetes cluster no matter where it is running. There is more to the Manage strategy then that as vRealize, CloudHealth and some other tools are also in that bucket.
 In addition VMware showed off Project Magna which is yet another SaaS solution that use AI/ML to collect data in a vast VMware data lake, learn from it and allow it to self-optimize and self-tune your environment for you. This will be integrated into vROPs and the first iteration of it appears to only support vSAN although I assume it will support any storage at some point.
In addition VMware showed off Project Magna which is yet another SaaS solution that use AI/ML to collect data in a vast VMware data lake, learn from it and allow it to self-optimize and self-tune your environment for you. This will be integrated into vROPs and the first iteration of it appears to only support vSAN although I assume it will support any storage at some point.
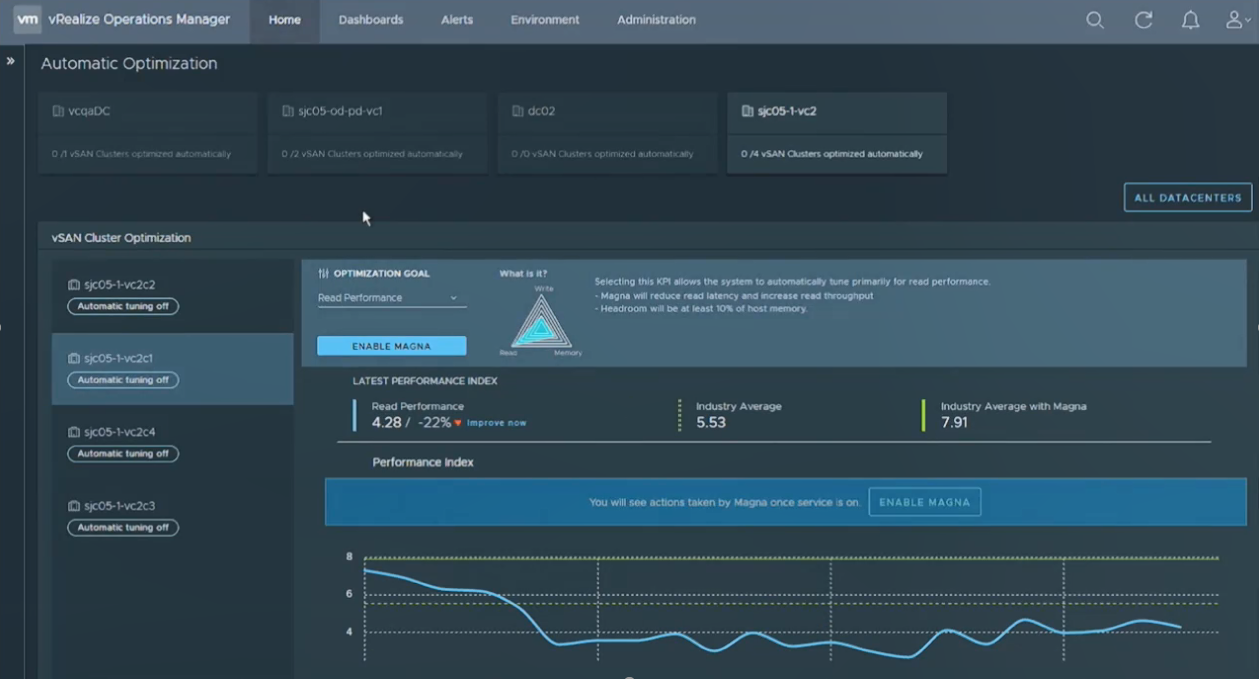 Combined this is a lot of new stuff that VMware is implementing and integrating into their portfolio, it makes sense from a strategic direction but you have to wonder how much more complexity and inter-dependency that this introduces into their product portfolio. Being a vSphere admin is way more complicated these days with clouds and containers in the mix when contrasted to the early days when you only had to worry about ESX & Virtual Center.
Combined this is a lot of new stuff that VMware is implementing and integrating into their portfolio, it makes sense from a strategic direction but you have to wonder how much more complexity and inter-dependency that this introduces into their product portfolio. Being a vSphere admin is way more complicated these days with clouds and containers in the mix when contrasted to the early days when you only had to worry about ESX & Virtual Center.
VMware also quietly announced new versions of their vRealize Suite (8.0) as well.
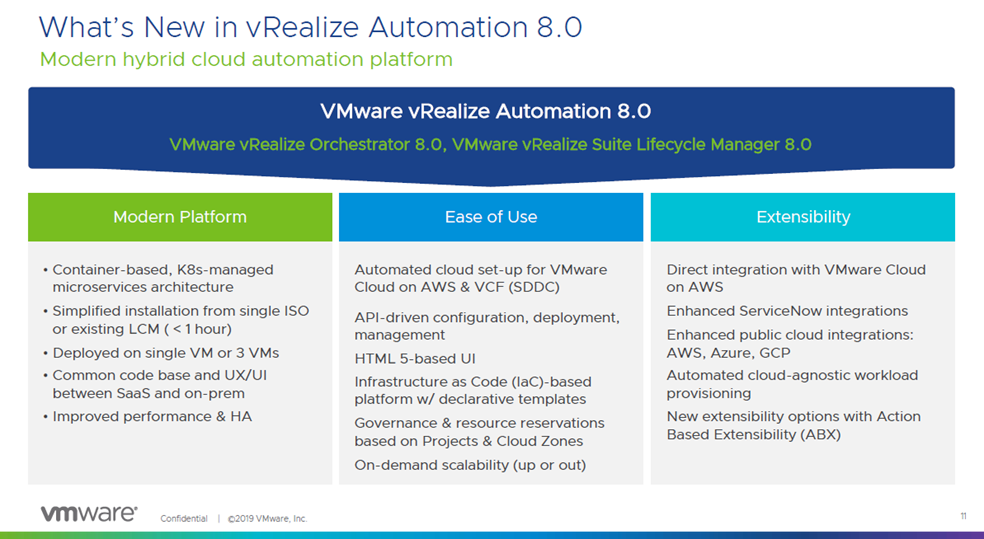
VMware Tanzu:
Project Pacific:
Project Tanzu Mission Control:
Project Magna:
How were the General Sessions?
I stopped attending the General Sessions live years ago and just watch it from my hotel via the live stream. Historically for me VMworld has had some good years and some bland years with their General Sessions. They definitely are different now compared to many years ago back in the Stephen Herrod days. That said I thought this years were about in the middle between good and bland. Day 1 with Pat Gelsinger largely featured all the Tanzu announcements and then followed up with cloud and networking announcements and customer interviews. It may just be me but I find customer interviews in keynotes extremely boring. You can watch the day 1 keynote here.
The Day 2 keynote mostly featured Ray O’Farrell who talked through a made up company, Tanzu Tees that had IT challenges but have no fear, VMware to the rescue. It was a decent demonstration of everything they announced on Day 1 including Project Pacific, Tanzu Mission Control, Magna and more. Near the end they brought out Greg Lavender who talked about Bitfusion and ARM stuff. At the end Pat Gelsinger announced Ray O’Farrell is the new leader of the Cloud Native NU and that Greg Lavender is the new CTO. I really like Ray, he reminds me of a kind, patient grandpa who is a great storyteller, we’ll have to see how Greg does in that prominent position.
How were the Breakout Sessions?
I actually didn’t sign up for many this year knowing that there was a 99% chance that I wouldn’t attend them at the event. I did attend (and present) a few key ones. I went to the vVols technical deep dive session by Jason Massae that has run for the last 5 years. The were a good amount of people there but attendance seemed about half of last year. As this session is largely similar content each year I imagine some people don’t repeat this session year after year.
 I also went to the vVols & SRM tech preview session that featured Velina Krestava who is the product manager for SRM and a presentitive from both Pure and HPE who are the only partners that support vVols replication to this day. This was a great session that was mostly full, Velina did a great job presenting and Cody & Bharath brought the vVols energy. There seemed to be a lot of interest in SRM support for vVols as expected because failover without SRM is a bit complicated.
I also went to the vVols & SRM tech preview session that featured Velina Krestava who is the product manager for SRM and a presentitive from both Pure and HPE who are the only partners that support vVols replication to this day. This was a great session that was mostly full, Velina did a great job presenting and Cody & Bharath brought the vVols energy. There seemed to be a lot of interest in SRM support for vVols as expected because failover without SRM is a bit complicated.
 I also was in the vVols industry tech panel which featured myself representing HPE, Andy Banta representing NetApp, Cody Hosterman representing Pure and Karl Owen representing Dell/EMC. The session was mostly Q&A and we had plenty of questions and comments in the room, also present was Bryan Young, the PM for vVols and Howard Marks, professional vVols heckler which made it interesting and fun.
I also was in the vVols industry tech panel which featured myself representing HPE, Andy Banta representing NetApp, Cody Hosterman representing Pure and Karl Owen representing Dell/EMC. The session was mostly Q&A and we had plenty of questions and comments in the room, also present was Bryan Young, the PM for vVols and Howard Marks, professional vVols heckler which made it interesting and fun.
 I’ll watch everything I missed via the VMworld On-Demand Library, unfortunately VMware has not made any sessions public this year, so you need a login to watch the sessions. They appear to be gated pretty well with authentication required for direct links to the videos although I was able to use Curl to download them to my PC once I authenticated with the site.
I’ll watch everything I missed via the VMworld On-Demand Library, unfortunately VMware has not made any sessions public this year, so you need a login to watch the sessions. They appear to be gated pretty well with authentication required for direct links to the videos although I was able to use Curl to download them to my PC once I authenticated with the site.
What was going on in the Solutions Exchange?
The usual stuff, being back in Moscone the layout was good and it was very roomy. The VMware booth was positioned in the middle towards the back. Overall it seemed pretty busy in there every time I was in there, the welcome reception was pretty busy but the food this year wasn’t all that great. Speaking of food as usual the lunches provided during the event were those dreadful box lunches with processed lunch meat (below), I couldn’t eat them so I just ate out every day.
 As far as booths go, overall it seemed like less bling and flashy then last year. Rubrik went big and flashy as usual with a 2nd booth again as a basketball court. Cohesity went big as well, Google Cloud had a prominent presence this year and a cool looking booth. The HPE booth which I helped with planning really popped this year. We had a cool military Polaris vehicle from SAIC in there and also a football theme going which culminated with Joe Montana appearing in the booth during the Hall Crawl. I was able to spend some time with Joe in the green room before he came out and he was very laid back and easy to talk to. Here’s a few pics from the Solutions Exchange.
As far as booths go, overall it seemed like less bling and flashy then last year. Rubrik went big and flashy as usual with a 2nd booth again as a basketball court. Cohesity went big as well, Google Cloud had a prominent presence this year and a cool looking booth. The HPE booth which I helped with planning really popped this year. We had a cool military Polaris vehicle from SAIC in there and also a football theme going which culminated with Joe Montana appearing in the booth during the Hall Crawl. I was able to spend some time with Joe in the green room before he came out and he was very laid back and easy to talk to. Here’s a few pics from the Solutions Exchange.




 vExpert Activities
vExpert Activities
VMware of course does a great job of coordinating activities for vExperts at VMworld, the marquis one being the vExpert party that Pat Gelsinger traditionally attends. The party was held at SPIN which is a ping pong bar close to Moscone and it was a great time as usual. Whenever Pat shows up he always get swarmed for pics but he’s a great sport and very easy to talk to. VMware also had a swag bag giveaway for vExperts which included a Raspberry Pi. There was also a few vendors still supporting the vExpert program, both Cohesity and Datrium had vExpert giveaways so thank you very much for that.


How about the parties?
There was definitely a lot less parties it seemed like, I think being in SF makes it harder to find party venues as well as more costly to throw parties. But there were still some parties that you could always find somewhere to go to each evening. On Sunday there was the annual VMunderground party which I attended, it was good to see a lot of old friends there. I went pretty light on parties this year, using a lot of the time to hang out with old friends, the only others parties I attended were the HyTrust party at the Press Club, the vExpert party and the VMworld Fest party.
The VMworld Fest shot up on my priority list once I found out Billy Idol was performing before One Republic. I love 80’s bands so that one was a must see for me. The VMworld Fest was a few blocks away at a a big auditorium, there was initially a huge line to get in as they has metal detectors and badge scanners at the front entrance. The line moved fairly fast though, the party was partly outside and inside where the band played. The auditorium had a large area in front of the stage where people can stand and seating all around that and up. I got there just in time to see Billy Idol and he was totally awesome, he’s very high energy and quite a showman and played all of his hits. After he played I went outside for beers and stogies with friends.




 After the party Bob Plankers, Jason Boche and I went back around the Marriott and smoked some stogies around back. We ran across Keith Norbie who was on a mission to make a beer run, on his way back I tagged along with him back to Andy Banta’s room where a lively Cards Against Humanity party was in progress. It was great hanging out there with old friends such as Howards Marks, Josh Atwell, Tim Antonowicz and Damian Karlson.
After the party Bob Plankers, Jason Boche and I went back around the Marriott and smoked some stogies around back. We ran across Keith Norbie who was on a mission to make a beer run, on his way back I tagged along with him back to Andy Banta’s room where a lively Cards Against Humanity party was in progress. It was great hanging out there with old friends such as Howards Marks, Josh Atwell, Tim Antonowicz and Damian Karlson.
Final Thoughts
As I stated earlier I thought this was one of the more enjoyable VMworld’s for a variety of reasons. I had some great times with old friends, overall the event was well executed despite being in SF, the networking was great and we did a lot around vVols (separate post on that coming). VMware had a lot to talk about on the container side which is really going to take vSphere in a new direction and it will be interesting to see how all that pans out. One thing is for sure, I better start brushing up on my Kubernetes knowledge, vSphere admins should as well as at some point they may become container admins as well. vSphere is getting a lot more complicated bringing more products and integrations into the mix which could have some potential downsides but as usual we’ll have to roll with the changes and adapt to it. Now that I’m back home and mostly caught up with the impact of being out a week it’s time to start watching the session replays and absorbing all that content. Overall it was a great event as usual and I look forward to the next one.
And here are some more pics:












 We had a dedicated vVols demo station in the HPE booth as well, also Jason Massae from VMware presented with me in a vVols session in the HPE booth and afterwords we recorded this short video interview on vVols that was posted on Twitter.
We had a dedicated vVols demo station in the HPE booth as well, also Jason Massae from VMware presented with me in a vVols session in the HPE booth and afterwords we recorded this short video interview on vVols that was posted on Twitter.
 I know Andy Banta from NetApp also presented on vVols in their booth as I happened to walk by during his presentation and I’m sure Cody Hosterman kept busy talking about vVols as well at the Pure booth.
I know Andy Banta from NetApp also presented on vVols in their booth as I happened to walk by during his presentation and I’m sure Cody Hosterman kept busy talking about vVols as well at the Pure booth. There was a decent amount of vVols sessions at VMworld this year. I’m not going to list them all here but I have a complete list in this post. If you didn’t catch them at VMworld definitely give the replays a watch. I’d like to highlight a few though here, the first and most exciting one was the tech preview of SRM support for vVols. It’s been a very long wait for this and after announcing it last year at VMworld it’s good to see VMware close to delivering it. There was good attendance at that session and a lot of good questions and Velina, Cody & Bharath did a great job presenting.
There was a decent amount of vVols sessions at VMworld this year. I’m not going to list them all here but I have a complete list in this post. If you didn’t catch them at VMworld definitely give the replays a watch. I’d like to highlight a few though here, the first and most exciting one was the tech preview of SRM support for vVols. It’s been a very long wait for this and after announcing it last year at VMworld it’s good to see VMware close to delivering it. There was good attendance at that session and a lot of good questions and Velina, Cody & Bharath did a great job presenting. There was also the usual vVols technical deep dive session by Jason Massae that has run for the last 5 years. The were a good amount of people there but attendance seemed about half of last year. As this session is largely similar content each year I imagine some people don’t repeat this session year after year but for those new to vVols it’s a good session to attend.
There was also the usual vVols technical deep dive session by Jason Massae that has run for the last 5 years. The were a good amount of people there but attendance seemed about half of last year. As this session is largely similar content each year I imagine some people don’t repeat this session year after year but for those new to vVols it’s a good session to attend. Now while all these sessions were recorded, only attendees can watch them which is unfortunate, I would sincerely hope VMware could post these to a public site as well as they would be great for the 99% of VMware customers who didn’t go to VMworld to be able to learn why they should consider migrating to vVols.
Now while all these sessions were recorded, only attendees can watch them which is unfortunate, I would sincerely hope VMware could post these to a public site as well as they would be great for the 99% of VMware customers who didn’t go to VMworld to be able to learn why they should consider migrating to vVols. Here’s Jason from VMware proudly displaying his new shirt.
Here’s Jason from VMware proudly displaying his new shirt. At my own expense I also had a new batch of vVols buttons made this year which were quickly gone. I even gave one to Pat Gelsinger who promptly put it on for the 2nd year in a row. Chatting with Pat briefly he called out HPE for helping lead the charge with vVols which was nice to hear.
At my own expense I also had a new batch of vVols buttons made this year which were quickly gone. I even gave one to Pat Gelsinger who promptly put it on for the 2nd year in a row. Chatting with Pat briefly he called out HPE for helping lead the charge with vVols which was nice to hear. Here’s Jason from VMware and Cody from Pure with their buttons on.
Here’s Jason from VMware and Cody from Pure with their buttons on. I’d also like to call out something that Lee Caswell posted right after the show were he explains why vVols has been slow early on and how it is much different today with vVols adoption expected to be at least 5% of the VMware install base in 2020 and on-track to triple in 2021. I’ll be doing another post shortly on vVols adoption.
I’d also like to call out something that Lee Caswell posted right after the show were he explains why vVols has been slow early on and how it is much different today with vVols adoption expected to be at least 5% of the VMware install base in 2020 and on-track to triple in 2021. I’ll be doing another post shortly on vVols adoption. Finally while VMworld 2019 US is over, VMworld 2019 EMEA is coming up soon and there is more vVols stuff on tap there.
Finally while VMworld 2019 US is over, VMworld 2019 EMEA is coming up soon and there is more vVols stuff on tap there.